With 78% of talent professionals and hiring managers saying that diversity is the top trend impacting how they hire, it is critical to take measures to remove as much bias from the hiring process as possible.
While there is no shortage of opinion that AI can be applied to reduce or remove human bias in hiring, there is a simple way of significantly mitigating unconscious bias at the top of the funnel without using AI and avoiding the risk of algorithmic bias: blind review and selection.
Blind Review and Selection

Whether you use “blind,” “anonymous,” “masked” or “obfuscated” to describe the technique, the goal and the end result are the same: prevent sourcers, recruiters and hiring managers from being unconsciously biased when reviewing and selecting applicants, resumes or profiles when considering people for employment.
If you cannot see a person’s name, you are mitigating unconscious bias as you are prevented from having any easy insight into a person’s gender, race or ethnicity.
If you cannot see where a person went to school (school name or country), you are prevented from exercising any unconscious bias you might have towards or against specific schools, and you also help mitigate unconscious bias with regard to race and/or ethnicity.
If you do not show when someone graduated from school, and if you impose a limit to the maximum number of years of experience to be visible (e.g., 10 where the job does not require more than 10), you prevent people from being unconsciously biased against people who have more than the required years of experience, and this can effectively combat ageism.
Solutions Pushing the Envelope
The good news is that there are already some solutions on the market today that offer blind results review and selection.
Eightfold.ai is a company I had the distinct honor of consulting with back in the fall of 2016. At the time I advised the team of what I believed to be a significant opportunity for their solution to help with diversity and inclusion. Since then, they have made many advancements in this space, including blind review and selection.
With Eightfold.ai, you can configure their solution to mask several profile elements that can mitigate unconscious gender, race, ethnicity, and age bias – and this includes people from within your ATS/CRM:
- Name
- Social Media/Picture
- Communication history
- Specific location
- Name of school
- Date of graduation
- More than 8 years of experience
Here is an example of a masked profile in their system:
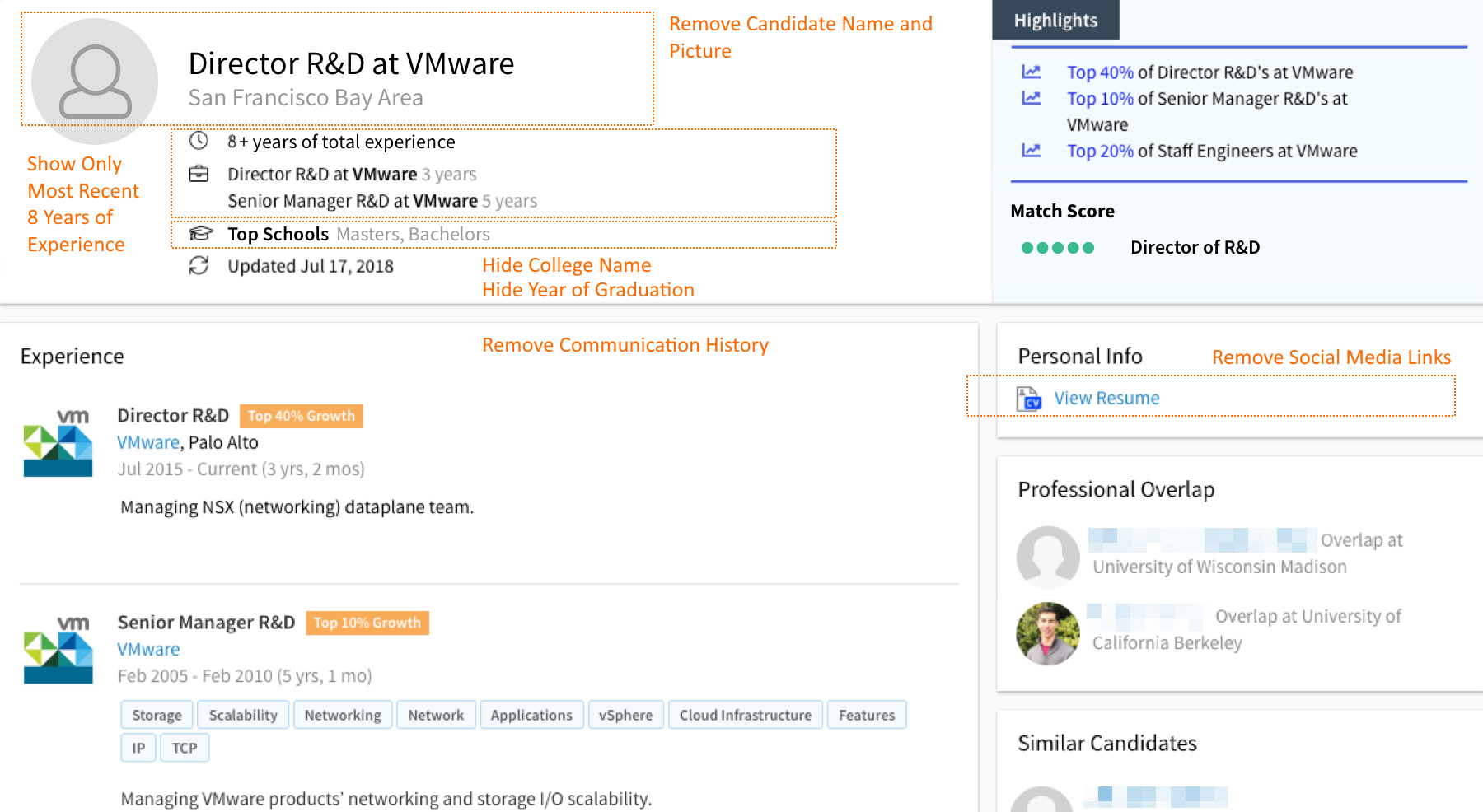
In case you were wondering, that person is a woman and she graduated with a Bachelor’s degree from a top university in India. But with the masked profile, it could just as easily be a man who graduated from Stanford, so there is no way a person could use the name and school/country to consciously or unconsciously discriminate against her.
So does this work?
The Eightfold team informed me that they recently completed a pilot with a multi-national company in which it was clear that for a specific set of roles, hiring managers preferred one gender over the other by 50% when selecting candidates for phone screen prior to rolling out the masked screening process. After the rollout of masked screening, there was virtually no difference in the selection rate between gender.
Entelo was an early mover in facilitating external diversity sourcing, and they have recently announced their “unbiased sourcing mode” where users are able to anonymize and hide many elements of profiles that are commonly associated with unconscious bias, including employment gaps and substituting gender-specific pronouns throughout the profiles.

Spire is another solution with blind review and selection capabilities, allowing you to match your applicants and other candidates to jobs without seeing names, pictures, universities, date of graduation or years of experience greater than required.
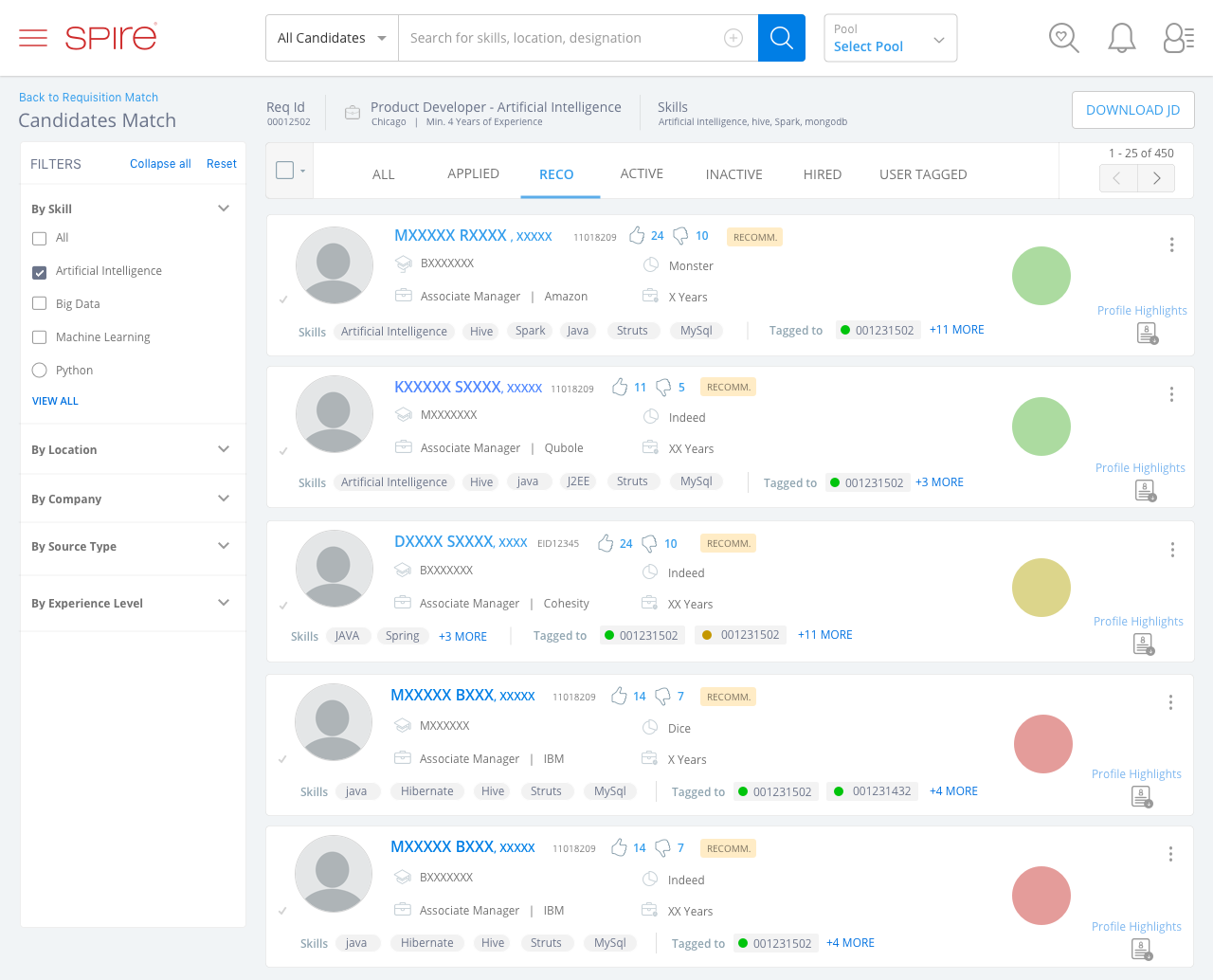
Another solution I am aware of that offers similar functionality is SeekOut. If you are aware of others, please let me know, and I would be happy to share them.
A Call to All HR Technology Solution Providers
I believe configurable blind review and selection should become a standard and required feature of any HR technology solution that involves reviewing applicants or resumes/profiles when considering people for employment, including internal mobility.
Without it, users are fully prone to the effects of unconscious bias when it comes to reviewing and selecting (or not!) applicants and potential candidates.
While blind review and selection don’t address unconscious bias that can creep into the interview and offer stages, it can practically eliminate it from the top of the talent funnel, leading to more diverse applicants and candidates getting into the hiring process in the first place.
If you caught my mention of algorithmic bias in the beginning of this post, stay tuned as I will be writing about the risks associated with using AI in sourcing and recruiting soon.

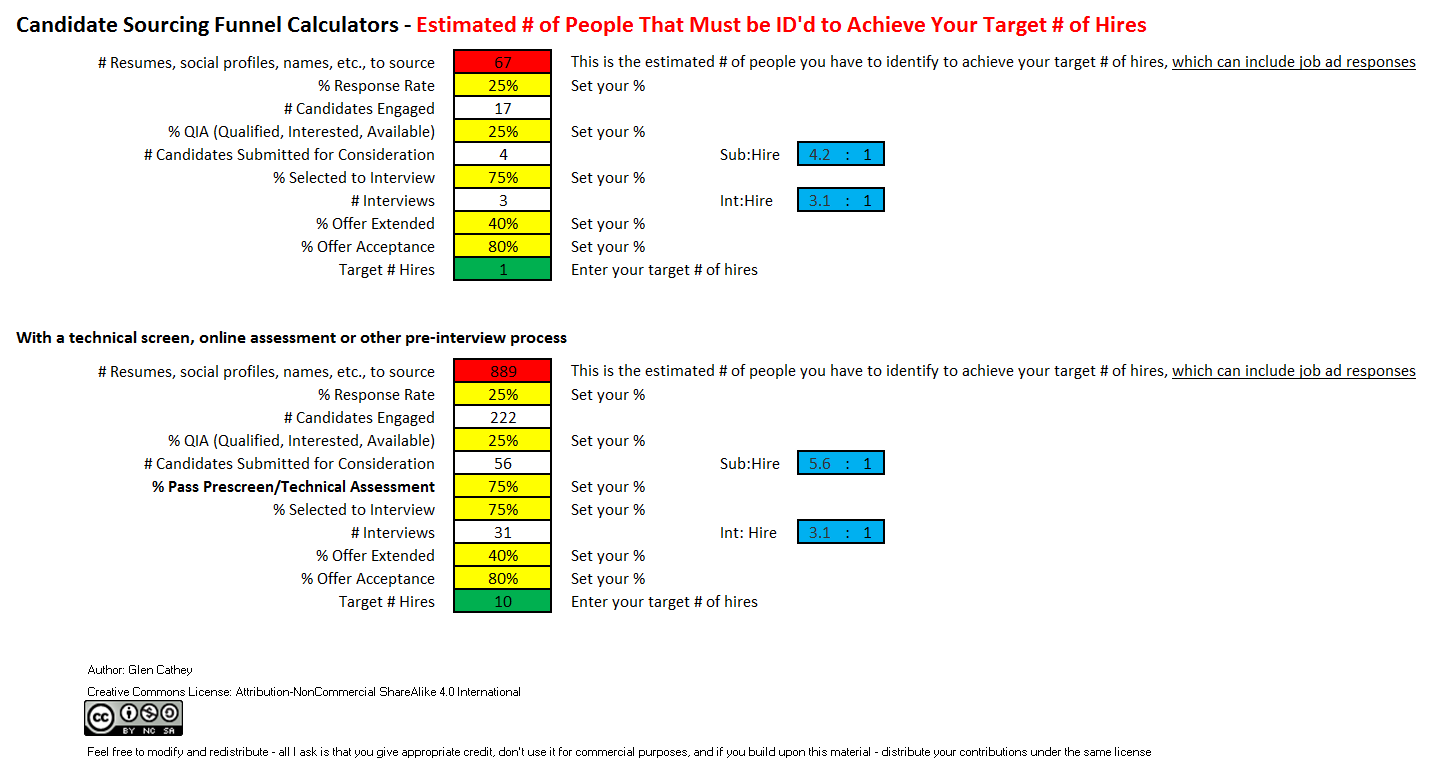
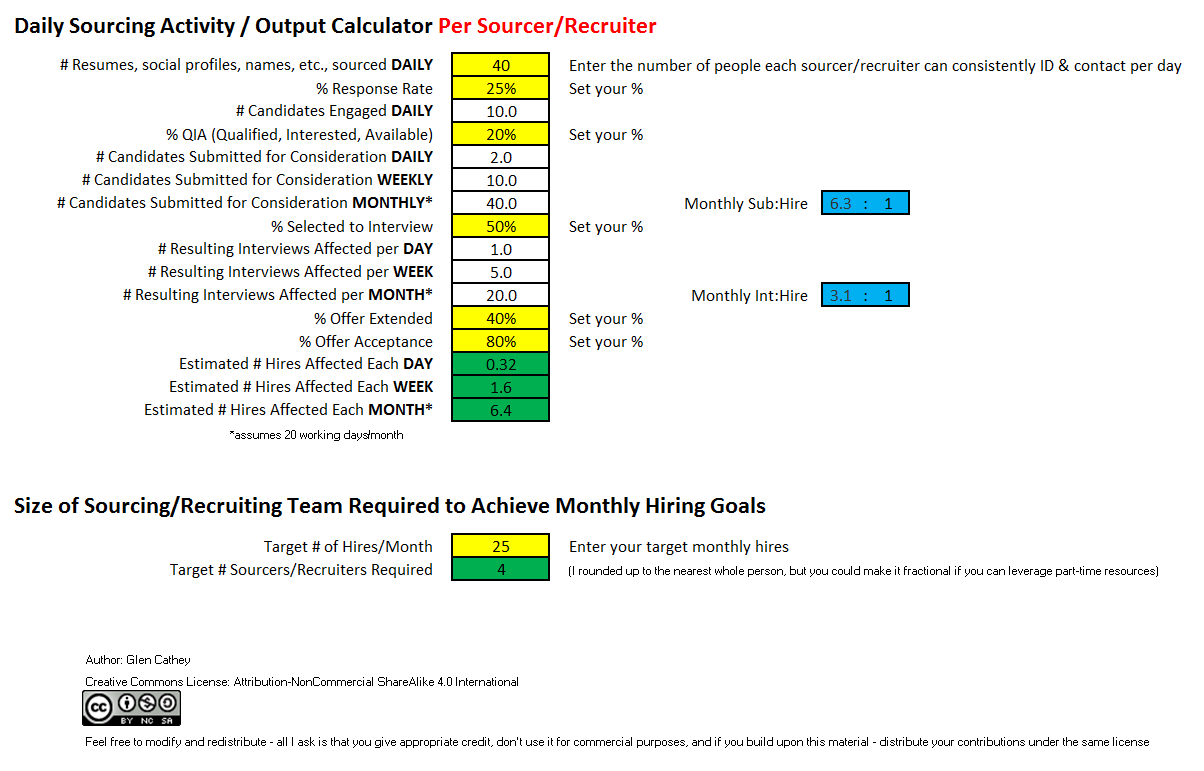
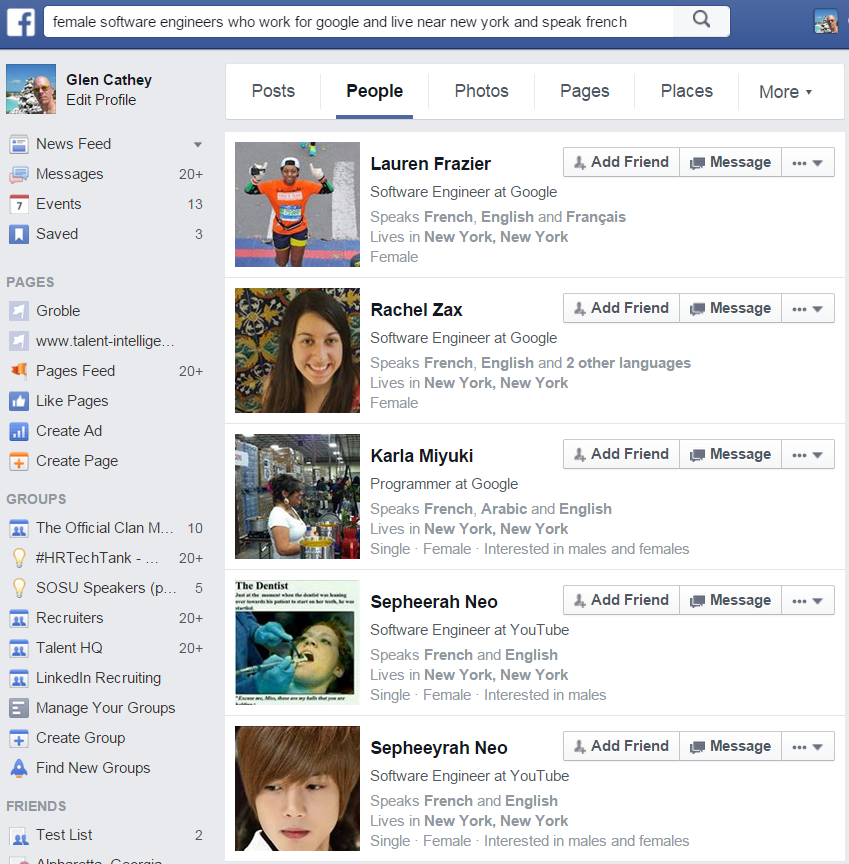
 There are people in the HR/recruiting industry who believe that searching databases, the Internet, and social networking sites to source talent is relatively easy and that it can be automated through the use of technology.
There are people in the HR/recruiting industry who believe that searching databases, the Internet, and social networking sites to source talent is relatively easy and that it can be automated through the use of technology.

 Have you ever wondered:
Have you ever wondered: